No granularity
Cloud billing shows what you spent on Bedrock or Azure OpenAI. It does not show which team, which application, or which developer drove it.

AI spend is driven by tokens, GPUs, inference profiles, and coding agents. PointFive is the AI Efficiency OS that helps engineering teams understand what's driving AI spend, identify and quantify waste across every layer of the stack, and enforce the controls needed to scale AI adoption responsibly.
Cloud billing shows what you spent on Bedrock or Azure OpenAI. It does not show which team, which application, or which developer drove it.
Every tool call a coding agent makes returns more output than it needs. Every token in that output gets charged. The waste happens automatically, regardless of how good the engineer or the model is.
Most teams have no way to set model policies, cap spend by team, or enforce which tools coding agents can access. Governance is manual at best.
Token management is probably one of the most critical pieces of the overall AI landscape because that is where you tend to blow your budget the fastest.
One platform across cloud AI services, gateways and observability, developer endpoints, and the data platform. Every layer feeds the same cost model.
Managed LLMs, model serving platforms, GPU infrastructure, and data platform AI services.
LiteLLM, LangFuse, and compatible gateway, tracing, and observability platforms.
Coding agents, AI-powered development tools, and endpoint AI usage.
Model serving inside the data warehouse, where AI workloads live next to the data.
Four specific differentiators built for AI workload economics, not generic cloud cost reporting.
Go beyond infrastructure costs to identify waste inside prompts, tool definitions, cache usage, and agent workflows.
Tokenomics is the unit of AI cost. Measure and optimize token consumption across models, applications, prompts, and coding agents.
Allocate spend at the deployment, application, team, prompt, and developer level with a granularity native cloud billing cannot provide.
Normalize spend across AWS, Azure, GCP, Snowflake, Databricks, OpenAI, Anthropic, and endpoint AI tools into a single view.
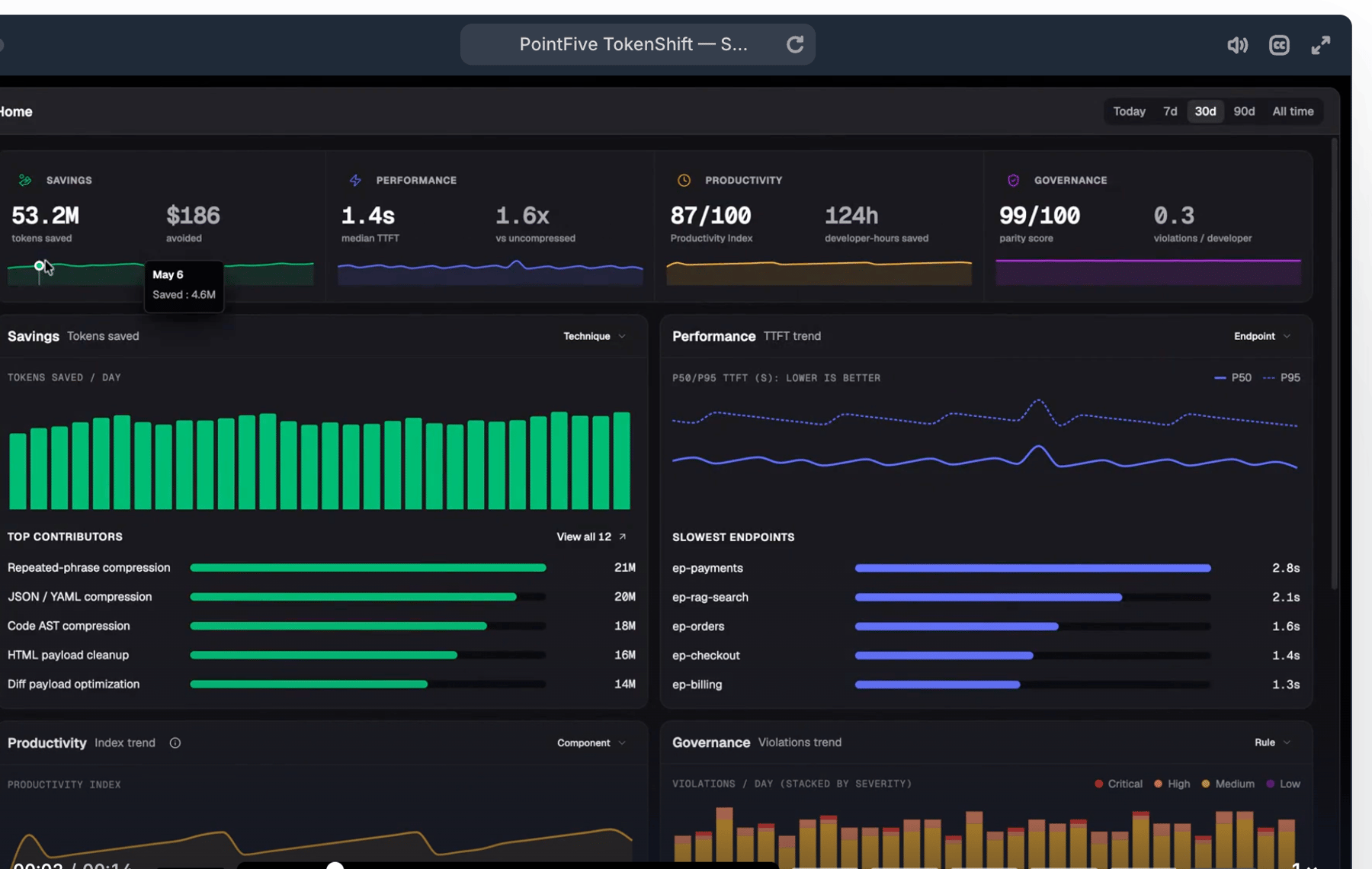
What PointFive customers see in their first weeks.
From cloud AI services and GPU infrastructure to coding agents and prompts.
Understand
Optimize
Govern
AI cost optimization is the practice of measuring, attributing, and reducing the cost of running AI workloads across the full stack: managed LLM APIs (Azure OpenAI, AWS Bedrock, GCP Vertex AI), GPU infrastructure, inference endpoints, data-platform model serving, and coding agents on developer machines. It goes beyond traditional cloud cost management by addressing token-based billing, prompt and tool-call waste, and endpoint AI usage that cloud billing never sees.
Traditional cloud cost management focuses on compute, storage, and networking with predictable pricing models. AI workloads introduce fundamentally different economics: token-based billing, provisioned-throughput vs. pay-as-you-go decisions, model-version efficiency differences, prompt-cache mechanics, and costs that scale non-linearly with usage. AI cost optimization requires understanding these mechanics at the deployment, prompt, and developer level, not just the billing account level.
PointFive connects to AWS, Azure, and GCP through agentless, read-only integrations and normalizes spend across providers into a single view. It also covers data-platform AI (Databricks Model Serving, Snowflake Cortex AI), LLM gateways and observability (LiteLLM, LangFuse), and developer-endpoint AI usage via TokenShift, so engineering leaders can see one number for AI spend regardless of where the workload runs.
Yes. PointFive automatically maps AI spend to teams, applications, prompts, and developers using your existing infrastructure topology and identity signals, so teams get real-time visibility into their AI footprint without manual tagging or spreadsheet reconciliation.
Savings vary by environment, but PointFive typically delivers a first set of savings opportunities within 48 hours, 10-20% reduction in coding-agent token consumption via TokenShift, and up to 80% savings through model migration and right-sizing of provisioned capacity.
PointFive uses agentless, read-only integrations that deploy in hours, not weeks. Most customers see their first AI cost insights and optimization recommendations within 48 hours of connecting their environment.
PointFive supports Azure OpenAI (GPT-5.5, o4-mini), AWS Bedrock (Claude, Amazon Nova, Titan (legacy), Llama, Mistral), and GCP Vertex AI (Gemini, custom models). It also covers GPU infrastructure across AWS, Azure, and GCP, data-platform AI (Databricks Model Serving, Snowflake Cortex AI), LLM gateways (LiteLLM, LangFuse), and coding agents (Claude Code, Cursor, GitHub Copilot, Devin Desktop, Codex) via TokenShift.
Yes. PointFive integrates with Jira, ServiceNow, and Slack for workflow, and its MCP server brings cost intelligence directly into Claude, Cursor, ChatGPT, VS Code, and other MCP-compatible tools, so engineers can investigate cost questions and act on optimization opportunities without leaving their workflow.
Connect your environment in under 15 minutes. PointFive starts finding savings immediately.