
Most optimization opportunities don't go unresolved because they're hard to find. They go unresolved because nobody gets around to fixing them.
Detached EBS volumes. Orphaned snapshots. Idle resources. Things everyone agrees should be cleaned up, but that stay in the backlog for months. This is the last-mile problem of optimization, and it hasn't really changed.
The default answer has been: automate it.
But after dozens of conversations with platform, cloud, and FinOps teams, a different reality shows up. Automation is already everywhere: scripts, workflows, internal tools, IaC pipelines. Capability isn't the issue. It's fit.
Teams don't struggle with whether something can be automated. They struggle with how yet another automation layer fits into everything they already run, without creating conflict with the controls and ownership models that already exist.
One customer put it simply during a recent review of our remediation capabilities: "We already automate things ourselves. We need to understand how your automation fits into our automation framework."
That's why we're launching Auto-Remediation.
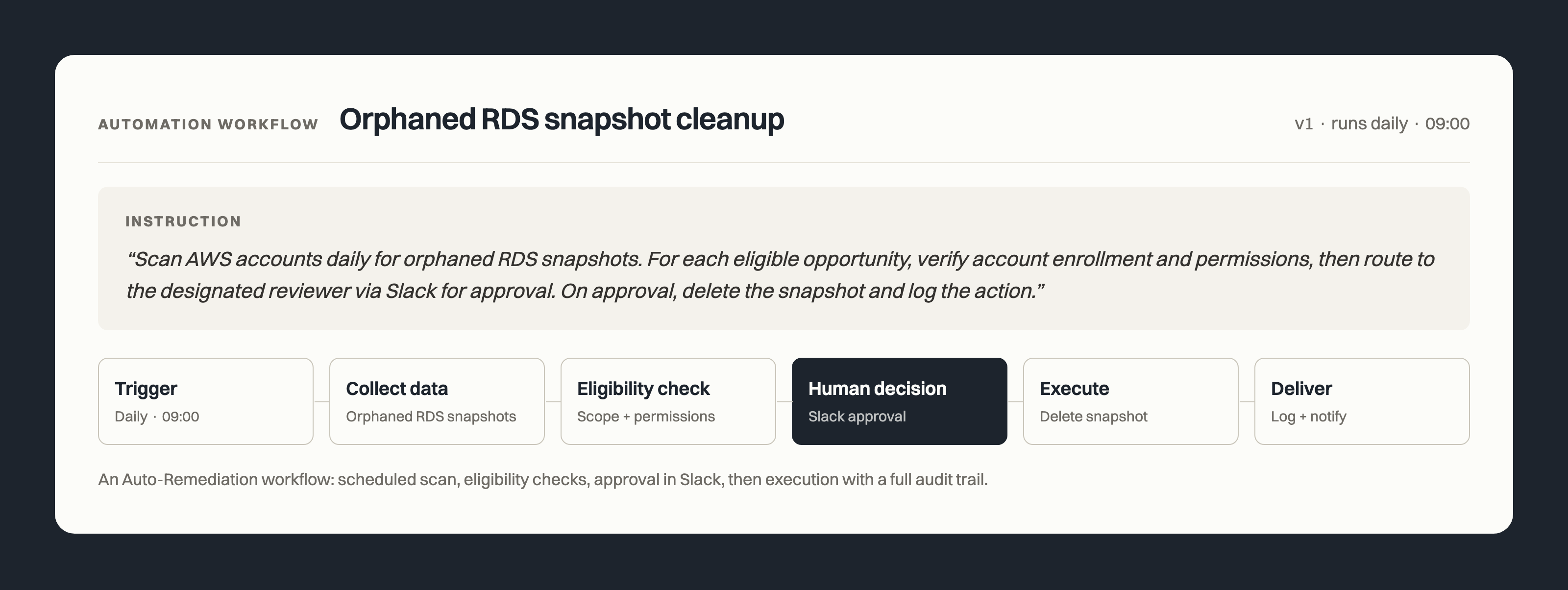
When optimization leaves the backlog
Auto-Remediation extends PointFive from finding optimization opportunities to executing approved fixes in AWS. The design principle was simple: it should fit into how your team already operates, not add a parallel system to manage.
You don't need to introduce new IAM roles or set up extra trust. Your existing PointFive role stays in place, and you decide which actions are permitted. Each remediation type is turned on individually, so you can enable what suits you now and leave the rest for later. Scope applies at the account or OU level, and new accounts added to an enrolled OU are covered automatically.
Before anything runs, PointFive checks a few things: that the opportunity type is supported, the account is in scope, and every required permission is present. If something's missing, it stops. AWS permissions alone don't decide whether an action runs.
Automated execution. Human approval.
The first question we usually get: "What stops this from deleting the wrong thing?"
Every workflow waits for a human to approve before anything executes.
When opportunities come up, the reviewer sees the resource, the planned action, and the estimated savings. They approve or skip. After approval, PointFive runs the change, updates the opportunity status, logs the action, and sends a notification to Slack, Teams, or email. Everything is traceable.
Why we started with six remediation types
We picked the first supported types based on what customers actually follow through on. Not what sounds useful in a demo. What gets acted on when the opportunity shows up.
The six types:
- Inactive and detached EBS volumes
- Unused EBS volumes attached to stopped EC2 instances
- Orphaned RDS cluster snapshots
- Orphaned RDS snapshots
- gp2 to gp3 volume upgrades
- Inactive VPC endpoints
None of these are complicated. They're just easy to agree on and hard to find time for. gp2 to gp3 is a good example: zero downtime, straightforward savings, and routinely stuck in backlogs because it's never the most urgent thing. Orphaned snapshots are the same story. Everyone knows they're there. Nobody prioritizes the cleanup.
Auto-Remediation just closes that loop: find it, check it, approve it, run it.
Getting started
The industry is already good at finding optimization opportunities. Consistently acting on them is the harder part, especially without breaking the processes teams already trust.
Auto-Remediation is available now for AWS customers.