
Scroll through r/googlecloud on any given week and you'll find the same post, with different numbers.
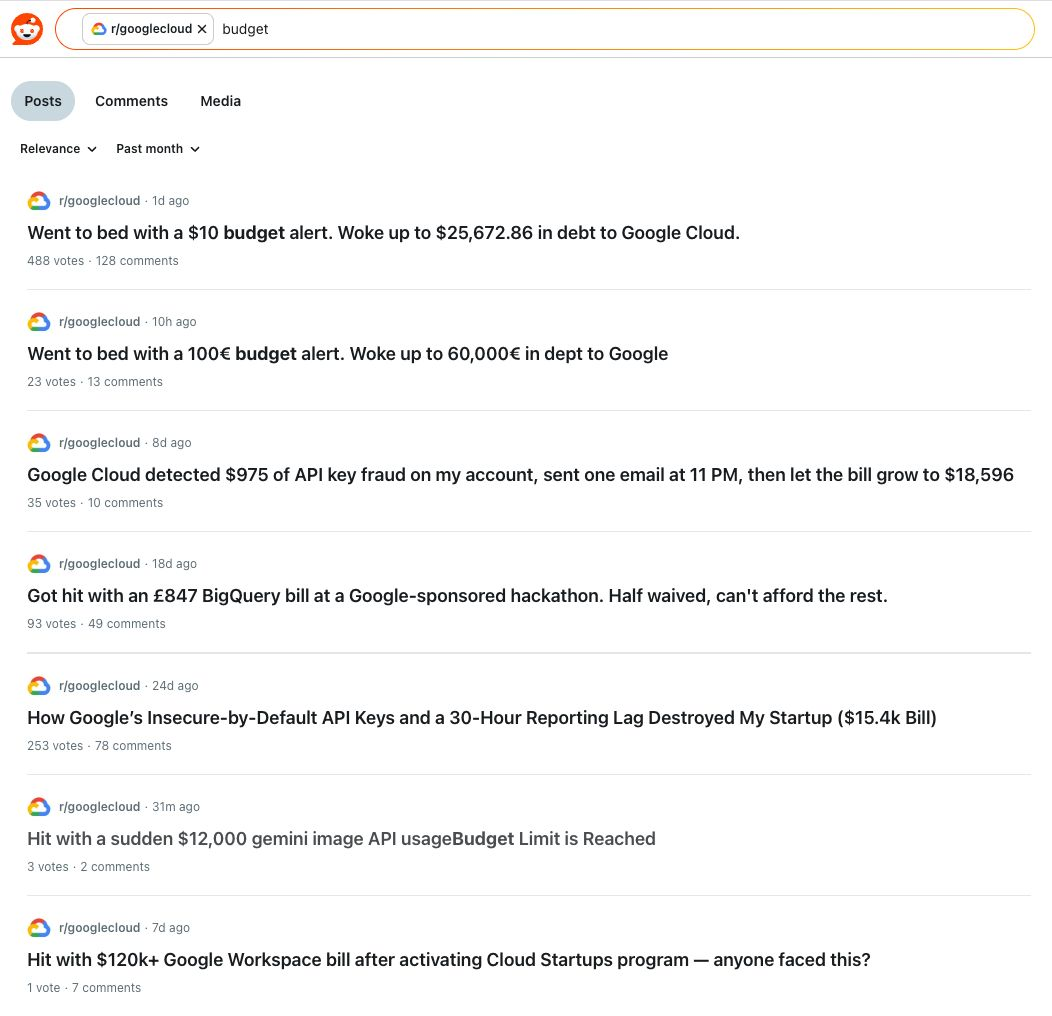
This isn't a billing bug. It's a detection problem. And the same pattern shows up on AWS and Azure, just with different subreddits.
Why Native Budget Alerts Don't Save You
Cloud providers offer budget alerts. They will not save you from this.
The reason is structural. Native budget alerts are built on top of the billing pipeline, and the billing pipeline runs on a delay. GCP's own documentation acknowledges that Cloud Billing data can take up to 24 hours to appear, sometimes longer. Anomaly detection inside Cost Explorer, Cost Management, and Billing all share the same constraint, they evaluate yesterday against the day before. By the time the threshold trips, the spike has already happened, and in many of these cases, finished happening.
The second problem is scope. Each cloud provider can only see itself. If your organization runs workloads across AWS and GCP, or AWS and Azure, every native tool gives you a partial picture. A leaked AWS key burning through Bedrock won't show up in your GCP console. A misconfigured BigQuery job won't trigger anything in CloudWatch. Each cloud watches its own perimeter, badly, and there's no shared view across them.
The third problem is granularity. Budget alerts trigger on totals. They tell you the bill is too high. They don't tell you which service, which resource, which key, or which engineer's deployment caused the change. By the time you've answered those questions, the war room is already half a day old.
What Actually Catches a Spike
Bill shock isn't prevented by alerts. It's prevented by detection that runs against the right data, on the right cadence, with the right context attached.
That's the design of PointFive's Cost Anomaly Detection. It evaluates usage and rate continuously against a learned baseline, not a static threshold. It uses Prophet, Meta's open-source forecasting model, to learn your seasonality, daily, weekly, monthly, yearly, so that a normal Tuesday batch job doesn't fire a page at 2 AM, but a brand-new $25K Bedrock inference run absolutely does. The detection runs across every account, every service, every region, and every cloud you've connected, so a spike in a forgotten dev project surfaces with the same signal as one in production.
That last part matters. The Reddit threads above are full of accounts where the spend came from a service the team had barely touched, an old API key, a hackathon project, a Workspace activation that quietly enrolled them in a paid program. Native alerts assume you'll be watching the services you actively use. The DeepWaste™ engine doesn't make that assumption. It watches everything, and it knows what "normal" looks like for each line item independently.
Finding the Spend, Not Just the Spike
A spike alert is a starting point. It's far more valuable when it arrives with the cause already identified, instead of three hours of investigation tacked on the front.
Every PointFive anomaly arrives with the breakdown already done. Was the change driven by usage volume or by effective cost per unit? A rate change usually means an expired discount or modified pricing terms. A usage change means an operational shift, a new deployment, a runaway script, a credential that shouldn't be live anymore. Each anomaly identifies its own contributors, the specific resources, services, tags, or accounts most likely responsible, by running the detection algorithm independently on each candidate dimension. You don't get "BigQuery cost is up." You get "this query, in this project, run by this service account, against this dataset, between these hours."
That's the difference between a war room and a ticket.
And Fixing It Before the Bill Lands
Detection without remediation is just a faster way to feel bad about the bill.
PointFive's anomaly module is wired into the same agentic remediation pipeline that powers the rest of the platform. When the system identifies a runaway resource, it can open a pre-filled Jira ticket with full context, route it to the owner, and provide the exact remediation playbook, scope down the key, kill the job, drop the verbose logging, throttle the deployment. The full loop, alerting, investigation, and resolution, happens in one place. No context-switching. No screenshot-and-paste into Slack. No oncall engineer learning your billing console at 3 AM.
This is what the Reddit threads are missing. Not better alerts. Not a smarter threshold. A different operating model, one where the spike is caught when it starts, the cause is identified before anyone files a ticket, and the fix is one click away from the alert that surfaced it.
The Operating Model Behind It
This is what Cloud Efficiency Posture Management actually means in practice. It's not a dashboard. It's a continuously-running detection layer that watches every cloud you operate, attributes every dollar to a resource, and routes every anomaly to the team that can fix it, before the bill closes.
Cloud providers will keep shipping features that are insecure by default. Engineers will keep leaking API keys. Hackathons will keep generating accidental £800 BigQuery bills. The question isn't whether the next spike happens, it's whether you find out at 11 PM, at 3 AM, or three weeks later when accounting closes the books.
PointFive's job is to make sure it's the first one, with the fix already attached.
See it in action: Request a demo and we'll walk through anomaly detection on a real environment, your or one of ours.