PwC's AI research team is building a custom 32-billion parameter LLM across a complex, multi-region training pipeline using cutting-edge GPU infrastructure—from NVIDIA H200s to preview-stage B300 Blackwell GPUs. With workloads spread across 8 AWS regions, traditional FinOps tools couldn't map the full pipeline or pinpoint where waste was hiding.
Solution
PointFive's DeepWaste™ Detection Engine mapped PwC's entire LLM training pipeline end-to-end—surfacing actionable inefficiencies across compute, storage, and data transfer that traditional tools cannot see.
Background
PwC, one of the world's leading professional services firms, is investing heavily in custom AI capabilities. The firm's AI research team operates a platform for training a custom 8-billion parameter large language model built on NVIDIA MegatronLM 2.0 and Amazon SageMaker HyperPod.
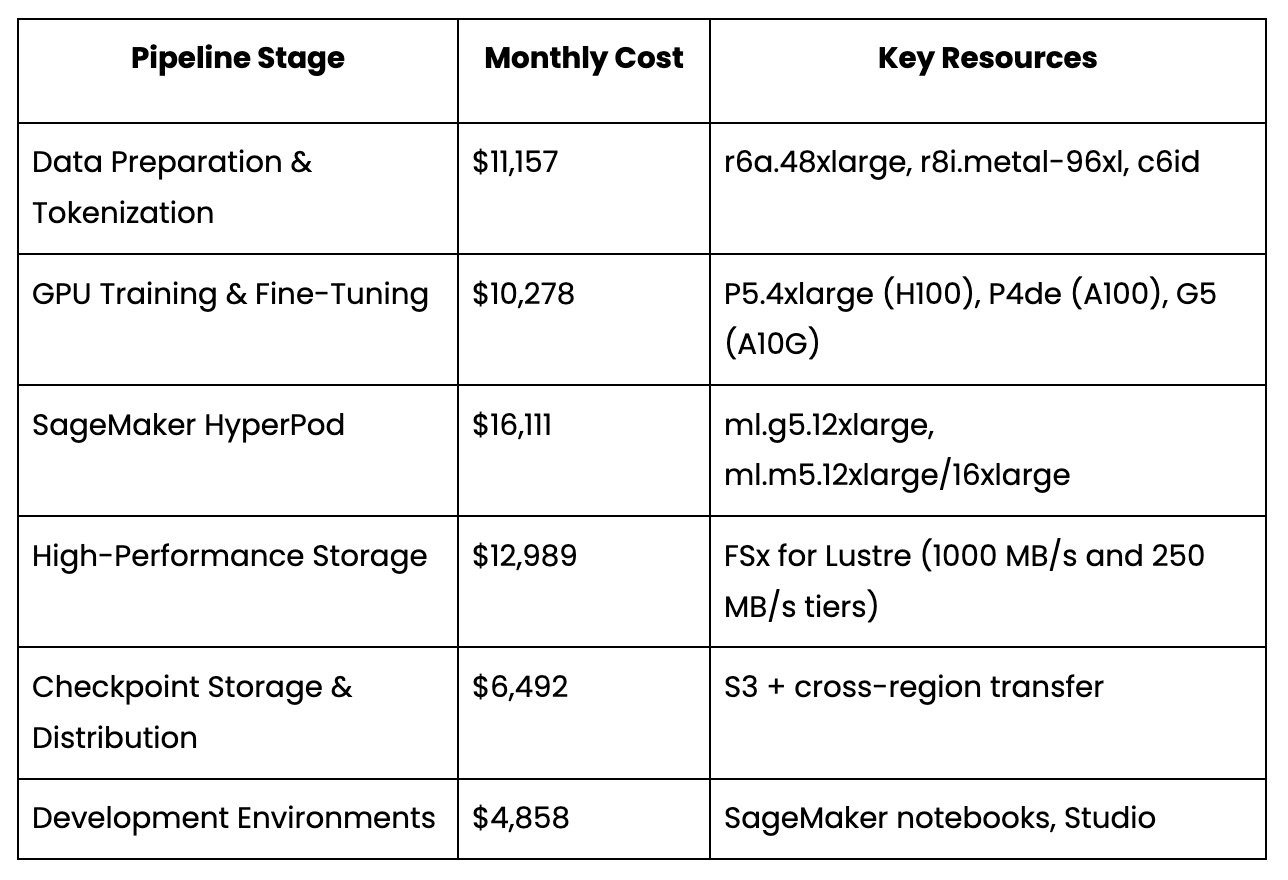
The training platform is a full ML pipeline: high-memory CPU instances handle data preparation and tokenization, GPU instances power instruction fine-tuning and model evaluation, and SageMaker HyperPod clusters run distributed training—all coordinated across 8 AWS regions with FSx for Lustre providing high-throughput storage and S3 managing checkpoint distribution.
At approximately $78K/month, with 99.6% of spend directly tied to AI/ML workloads, even modest percentage improvements translate into meaningful savings—and the team needed confidence that optimizations wouldn't disrupt a training pipeline where a single misconfiguration could waste days of GPU time.
Challenges
Multi-region pipeline complexity: The training pipeline spans us-east-1 (checkpoint hub), ap-south-1 (primary GPU training), us-east-2 (HyperPod + data prep), us-west-2 (Blackwell testing), and 4 additional regions. A checkpoint transfer cost in us-east-1 is meaningless without understanding it feeds a training job in ap-south-1.
Mixed compute paradigms: GPU workloads run across standalone EC2 instances, SageMaker HyperPod clusters, SageMaker Training Plans, Capacity Block reservations, and AWS Preview instances—each with different pricing models. No single AWS tool provides a unified view.
Cutting-edge hardware with no pricing history: PwC is among the earliest adopters of NVIDIA Blackwell GPUs, currently running 689 hours/month at $0 during AWS Preview. When GA pricing takes effect, this becomes a significant new cost center with no historical data to plan around.
High stakes, low tolerance for disruption: Training an 8B-parameter model is a multi-week process. The team needed optimization recommendations they could trust.
Objectives
Map the full AI training pipeline across all compute, storage, and data transfer components spanning 8 AWS regions
Identify waste in GPU and ML infrastructure across SageMaker, EC2 GPU instances, FSx storage tiers, and cross-region data flows
Prepare for Blackwell cost impact before NVIDIA Blackwell (P6) instances transition from AWS Preview to GA pricing
Deliver actionable, prioritized recommendations with engineering-ready remediation steps
Solution
PwC adopted PointFive to bring structure and visibility to their LLM training infrastructure.
End-to-End Pipeline Mapping
The DeepWaste™ Detection Engine identified and mapped every component of the training pipeline—attributing costs and data flows across all 8 regions.
Multi-Layer Cost Analysis
Key Discoveries
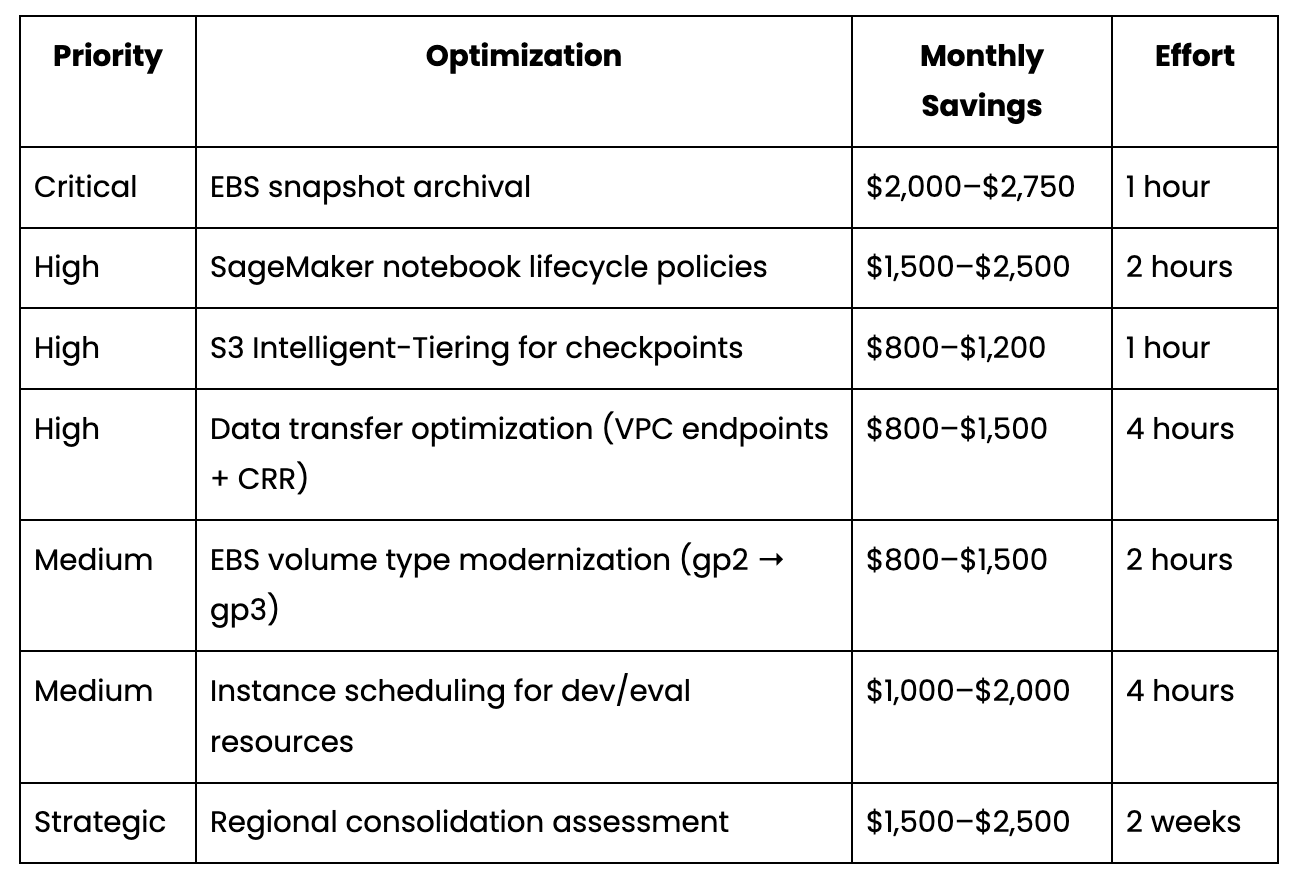
$2,750/month in dormant snapshot storage—ideal for archive tier at 75% savings
Over-provisioned FSx throughput when actual I/O patterns could be served by a lower tier
Cross-region checkpoint transfer waste without S3 Cross-Region Replication
Development instances running outside working hours
Results
$9K–$15K/month in Identified Savings (11–19% of Total Spend)
Validated existing good practices: PointFive confirmed that PwC's use of SageMaker Training Plans and EC2 Capacity Blocks for H100 reservations were well-optimized.
Blackwell cost preparedness: With 689 hours/month of P6 Blackwell GPU usage currently at $0, PointFive established a monitoring baseline for when GA pricing takes effect—estimated at $50K–$100K/month.
Full pipeline visibility: For the first time, PwC's AI research team had a single view connecting data preparation costs to training costs to checkpoint distribution costs across regions.
Conclusion
PwC's LLM training platform represents a new class of cloud workload: multi-region, multi-architecture, rapidly evolving, and mission-critical. Traditional FinOps tools see services and line items, not training pipelines and data flows.
PointFive mapped a full LLM training pipeline across 8 AWS regions, 5 NVIDIA GPU generations, and multiple compute paradigms into a coherent cost picture with prioritized, engineering-ready optimizations.
With $9K–$15K/month in savings identified and continuous monitoring in place for the coming Blackwell cost transition, PwC is positioned to scale its custom AI capabilities with cost efficiency built into the foundation.
Nubank
Nubank is one of the world's largest independent digital banks, serving over 100 million customers across Latin America. Headquartered in Brazil, the company operates a large and complex AWS environment that supports a broad portfolio of financial products and more than 7,000 engineers.
A Mature FinOps Practice Hit a Ceiling
Nubank spent years maturing its FinOps practice through internal initiatives and with the support of a well known Cloud Cost Management tool. The platform delivered meaningful value. Nubank gained visibility into cloud spend across accounts, regions, and services, improved budgeting and forecasting accuracy, and tracked cost units across the organization.
Each of Nubank's 50 business units had a dedicated Cost Champion responsible for managing cloud spend against budget. From a FinOps perspective, Nubank had done what many organizations are still working toward.
Despite this maturity, gaps remained. Cost Champions could see rising costs, spikes, and budget deviations, but they could not explain why those changes occurred. Reviewing budgets from current and prior years showed trends, not causes. Without root cause, teams could only react.
Suspected inefficiencies inside AWS were difficult to validate. Central Platform teams occasionally raised concerns, such as the use of incorrect database table classes, but those concerns often stalled. Without clear context, ownership, or an easy way to engage engineering teams, recommendations were hard to act on.
It became clear that Nubank was not missing visibility. It was missing causality, ownership, and a practical path to remediation.
Extending FinOps Beyond Visibility
Nubank adopted PointFive to extend its existing tooling, not replace it. The CCM platform remained the source of truth for cost transparency and reporting. PointFive focused on identifying inefficiencies and turning them into actionable remediation.
Once PointFive received read-only access to Nubank's AWS environment, it began detecting more than 200 types of waste across configuration, architecture, data lifecycle, and application behavior. Each opportunity appeared with estimated savings, risk level, remediation difficulty, and the full context required to validate the issue.
The results were immediate. By following PointFive's remediation workflows, Nubank engineers remediated enough waste to exceed the annual cost of PointFive in ten days (while still in the proof of concept).
Making Efficiency Actionable at Scale
Onboarding took less than a week. Nubank shared its internal AWS tagging structure, and PointFive's customer success team mapped resources to the correct business units, Cost Champions, and engineering owners. This ensured opportunities routed directly to accountable teams without creating additional work for Nubank.
PointFive's approach shifted efficiency ownership from a centralized FinOps function to the teams responsible for the infrastructure. Engineers saw opportunities tied directly to their resources, along with the context needed to validate them quickly and the ability to remediate through existing workflows in tools like Jira and ServiceNow.
Trust played a critical role in adoption. Engineers trusted PointFive's recommendations because they were specific, contextualized, and independently validated. Each opportunity clearly explained the root cause, the cost impact, the recommended remediation, and the associated risk.
Measurable Outcomes
Since adopting PointFive, Nubank has reduced its annual cloud spend by millions and lowered monthly cloud costs by approximately 5 percent. These results came not from one time cost cutting, but from sustained remediation at scale.
PointFive continues to detect more than 200 types of waste across Nubank's AWS environment, including misconfigured DynamoDB table storage classes, missing intelligent tiering on S3 buckets, suboptimal storage regions, inactive EBS volumes, and non archival data stored in non archival classes.
With more than 7,000 engineers, cost efficiency had historically competed with delivery, security, and compliance priorities. PointFive changed that dynamic. Engineers now engage directly with efficiency opportunities as part of their daily work, supported by clear ownership, trusted data, and simple remediation paths.
By extending its existing FinOps tooling with PointFive, Nubank moved beyond cost visibility to continuous cloud efficiency, where every team can see, validate, and resolve inefficiencies at speed.