.png)



Overview

Challenge
PwC's AI research team is building a custom 32-billion parameter LLM across a complex, multi-region training pipeline using cutting-edge GPU infrastructure—from NVIDIA H200s to preview-stage B300 Blackwell GPUs. With workloads spread across 8 AWS regions, traditional FinOps tools couldn't map the full pipeline or pinpoint where waste was hiding.

Solution
PointFive's DeepWaste™ Detection Engine mapped PwC's entire LLM training pipeline end-to-end—surfacing actionable inefficiencies across compute, storage, and data transfer that traditional tools cannot see.

Cloud Providers


Results at a Glance
- $78K/month in AI/ML infrastructure fully mapped and attributed across 8 regions
- $9K–$15K/month in savings identified (11–19% cost reduction)
- 5 NVIDIA GPU architectures optimized (Blackwell, Hopper, Ampere, Turing)
- Continuous monitoring established for NVIDIA Blackwell GA pricing transition
- Prioritized remediation plan delivered in actionable, phased engineering steps
Background
PwC, one of the world's leading professional services firms, is investing heavily in custom AI capabilities. The firm's AI research team operates a platform for training a custom 8-billion parameter large language model built on NVIDIA MegatronLM 2.0 and Amazon SageMaker HyperPod.
The training platform is a full ML pipeline: high-memory CPU instances handle data preparation and tokenization, GPU instances power instruction fine-tuning and model evaluation, and SageMaker HyperPod clusters run distributed training—all coordinated across 8 AWS regions with FSx for Lustre providing high-throughput storage and S3 managing checkpoint distribution.
At approximately $78K/month, with 99.6% of spend directly tied to AI/ML workloads, even modest percentage improvements translate into meaningful savings—and the team needed confidence that optimizations wouldn't disrupt a training pipeline where a single misconfiguration could waste days of GPU time.
Objectives
- Map the full AI training pipeline across all compute, storage, and data transfer components spanning 8 AWS regions
- Identify waste in GPU and ML infrastructure across SageMaker, EC2 GPU instances, FSx storage tiers, and cross-region data flows
- Prepare for Blackwell cost impact before NVIDIA Blackwell (P6) instances transition from AWS Preview to GA pricing
- Deliver actionable, prioritized recommendations with engineering-ready remediation steps
Challenges
Multi-region pipeline complexity: The training pipeline spans us-east-1 (checkpoint hub), ap-south-1 (primary GPU training), us-east-2 (HyperPod + data prep), us-west-2 (Blackwell testing), and 4 additional regions. A checkpoint transfer cost in us-east-1 is meaningless without understanding it feeds a training job in ap-south-1.
Mixed compute paradigms: GPU workloads run across standalone EC2 instances, SageMaker HyperPod clusters, SageMaker Training Plans, Capacity Block reservations, and AWS Preview instances—each with different pricing models. No single AWS tool provides a unified view.
Cutting-edge hardware with no pricing history: PwC is among the earliest adopters of NVIDIA Blackwell GPUs, currently running 689 hours/month at $0 during AWS Preview. When GA pricing takes effect, this becomes a significant new cost center with no historical data to plan around.
High stakes, low tolerance for disruption: Training an 8B-parameter model is a multi-week process. The team needed optimization recommendations they could trust.
Solution
PwC adopted PointFive to bring structure and visibility to their LLM training infrastructure.
End-to-End Pipeline Mapping
The DeepWaste™ Detection Engine identified and mapped every component of the training pipeline—attributing costs and data flows across all 8 regions.
Multi-Layer Cost Analysis
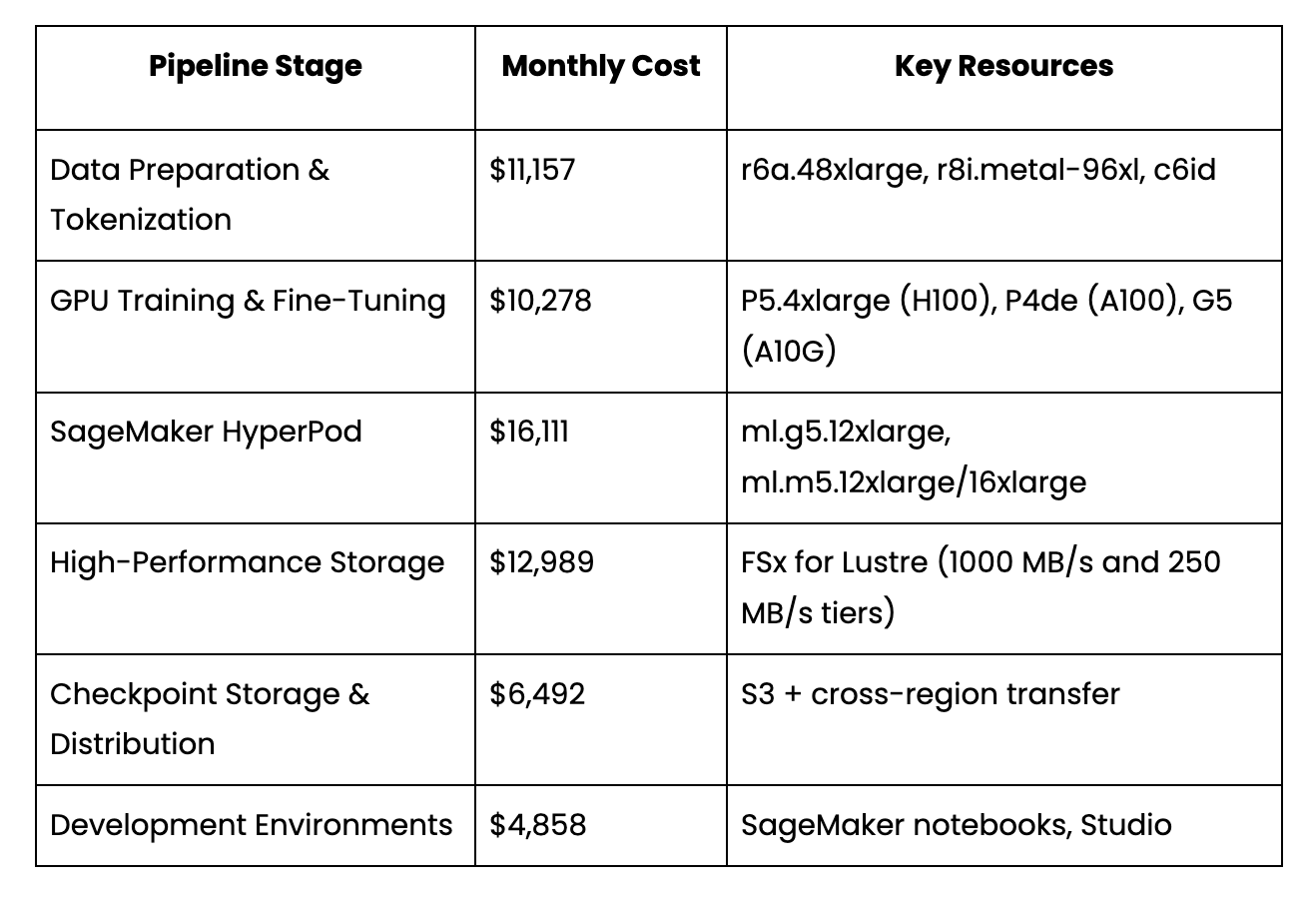
Key Discoveries
- $2,750/month in dormant snapshot storage—ideal for archive tier at 75% savings
- GPU notebooks running 24/7 for ~35% utilization—a straightforward lifecycle policy fix
- Over-provisioned FSx throughput when actual I/O patterns could be served by a lower tier
- Cross-region checkpoint transfer waste without S3 Cross-Region Replication
- Development instances running outside working hours
Results
$9K–$15K/month in Identified Savings (11–19% of Total Spend)

Validated existing good practices: PointFive confirmed that PwC's use of SageMaker Training Plans and EC2 Capacity Blocks for H100 reservations were well-optimized.
Blackwell cost preparedness: With 689 hours/month of P6 Blackwell GPU usage currently at $0, PointFive established a monitoring baseline for when GA pricing takes effect—estimated at $50K–$100K/month.
Full pipeline visibility: For the first time, PwC's AI research team had a single view connecting data preparation costs to training costs to checkpoint distribution costs across regions.
Conclusion
PwC's LLM training platform represents a new class of cloud workload: multi-region, multi-architecture, rapidly evolving, and mission-critical. Traditional FinOps tools see services and line items, not training pipelines and data flows.
PointFive mapped a full LLM training pipeline across 8 AWS regions, 5 NVIDIA GPU generations, and multiple compute paradigms into a coherent cost picture with prioritized, engineering-ready optimizations.
With $9K–$15K/month in savings identified and continuous monitoring in place for the coming Blackwell cost transition, PwC is positioned to scale its custom AI capabilities with cost efficiency built into the foundation.









